Levente Szabo
M.S. Computer Science
New York University 2021
Email: levbszabo@gmail.com
View My LinkedIn Profile
Implementation and Evaluation of the DANCER Framework for Academic Article Summarization
Joint Work: Aathira Manoj, Minji Kim
Overview Document summarization for academic articles is complicated by the document length, diversity and specialization of its vocabulary. The DANCER (Divide ANd ConquER) framework exploits the discourse structure of the document and uses sentence similarity to break a long document and its summary into multiple source-target pairs, which are used to train a summarization model. We assess the efficacy of the DANCER framework by using Pointer Generator as the summarization model and pairing it with different scoring metric (ROUGE-L, BLEU) for generating training samples. We evaluate its performance against a baseline model, which does not use DANCER. We use a subset of the publicly available arXiv dataset for our experiments.
1. Divide and Conquer
The Divide-ANd-ConquER (DANCER) 1 framework exploits the discourse structure of long documents, by working on each section separately. It does so by decomposing the summary of the document into sections and pairing it with the appropriate sections in order to create distinct target summaries. A neural network model is then trained to learn to summarize each part of the document separately using these target summaries. Finally, the partial summaries generated by the model are then combined to produce a final complete summary
Academic articles are an ideal candidate for long document summarization because the paper abstract can serve as a label or a candidate summary for the paper. Additionally many papers follow a general structure with Introduction, Methods, Results and Conclusion being common sections in most articles. We can improve the summarization output and reduce computational costs by taking advantage of this common structure.
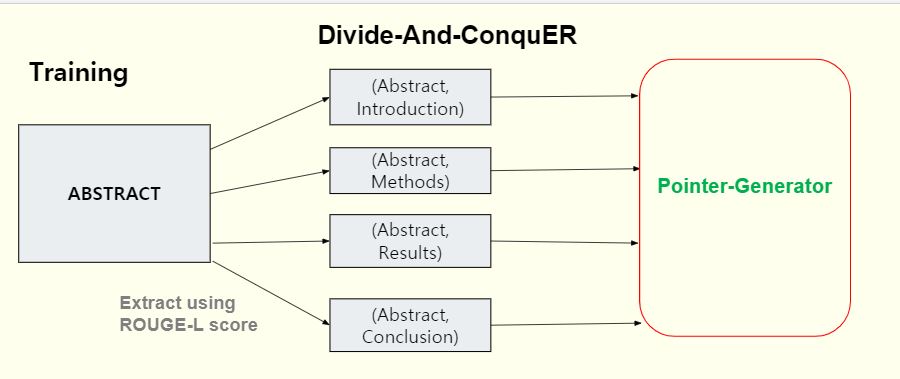
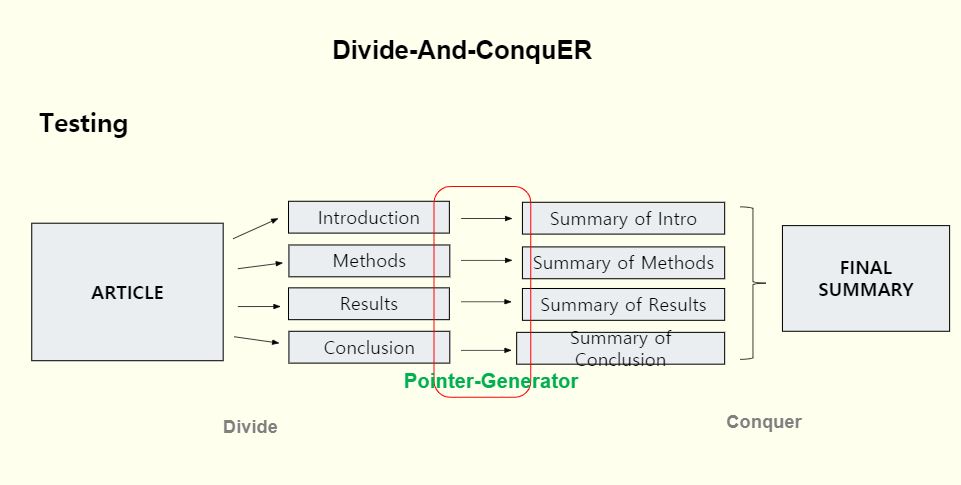
2. Problem Statement
Our goal is to evaluate and compare the performance of DANCER by using different scoring metrics for splitting the document summary into different sections. In particular, we use ROUGE-L 2 and BLEU 3 scores to generate the section-wise summaries from the main summary for training. We use the Pointer Generator, based on the sequence-to-sequence RNN paradigm, as the main summarization model. Finally, we compare the performance of the DANCER model with a baseline model, which also uses Pointer Generator, but does not split the main summary into section-wise summaries. We use a subset of a publicly available pre-processed ArXiv dataset for our experiments. The performance of different models is evaluated using ROUGE scores.
A general outline of our approach is given below.
- Use the DANCER method to generate training datasets using the ROUGE-LCS score and the BLEU-Corpus score. Generate a baseline dataset which does not use this approach.
- Train Pointer Generator Seq2Seq summarizer separately on all these datasets.
- While testing, use the trained weights of the Pointer Generator model to generate section-wise summaries and concatenate them to generate the final summary .
- Evaluate the different models according to different ROUGE scores.
3. Pointer Generator Model
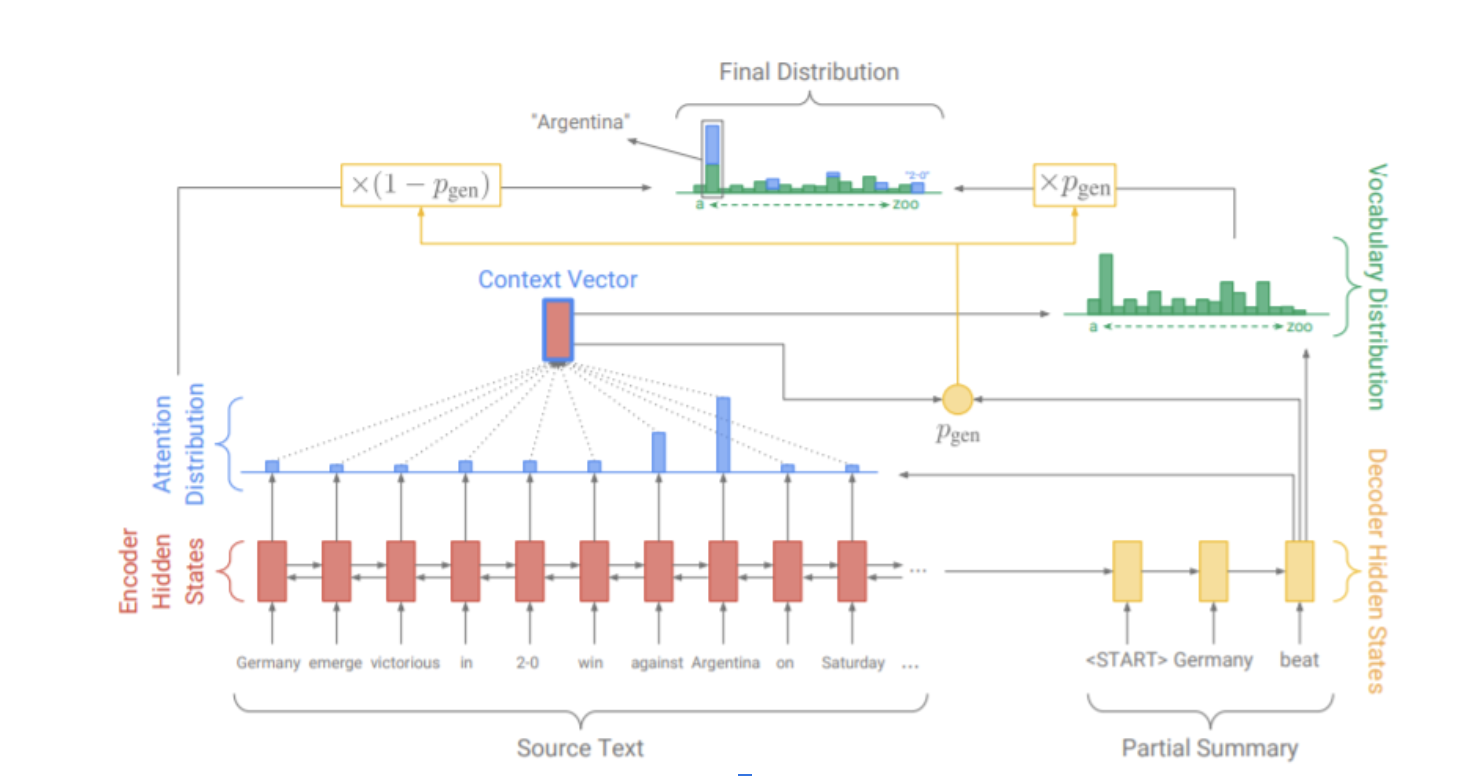
The Pointer Generator 4 is a sequence to sequence neural model that provides abstract text summarization. The model consists of an encoder and decoder phase. Through a combination of pointing at words in the source text and generating words from the vocabulary distribution this model can be seen as a hybrid summarization model. The model uses a coverage mechanism to minimize the repetition of copied words.
The input source text is embedded and fed into a bidirectional LSTM, the red network in the diagram. This network serves as the encoder and produces a set of hidden states. Decoding takes place one token at a time. For each timestep the decoder gives rise to decoder states which during training correspond to the word embedding of the previous word. Together these combine to create the attention distribution.
Next using the attention distribution the context vector is constructed as a dot product between the attention distribution and the hidden states. The attention distribution guides the decoder towards the next word while the context vector serves to produce the distribution over all words in the vocabulary P(x) as well as the pointer generator probability W which gives us the option to copy words from the source text according to S(x), the source distribution. Output tokens are produced according to
F(x) = W*P(x) + (1-W)*S(x)
4. Results
To test the efficacy of the DANCER framework we compared a baseline Pointer Generator model against one which used the ROUGE-LCS and one which used the BLEU scores to split summaries. We trained on 8000 articles and tested on 1000 articles. The results indicate the ROUGE-LCS as being superior on a variety of metrics when compared to both the BLEU and Baseline model.

Finally we show an example of a target abstract with both the ROUGE and BLEU summaries. One can see evidence of both source and vocab distributions.

[1]: Alexios Gidiotis and Grigorios Tsoumakas. 2020. A divide-and-conquer approach to the summarization of long documents
[2]: Chin-Yew Lin. 2004. ROUGE: A package for automatic evaluation of summaries. In Text Summarization Branches Out, pages 74–81, Barcelona, Spain. Association for Computational Linguistics.
[3]: Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. 2002. Bleu: A method for automatic evaluation of machine translation. ACL ’02, page 311–318, USA. Association for Computational Linguistics
[4]: Abigail See, Peter J. Liu, and Christopher D. Manning. 2017. Get to the point: Summarization with pointer-generator networks.