Levente Szabo
M.S. Computer Science
New York University 2021
Email: levbszabo@gmail.com
View My LinkedIn Profile
Implementation of a Probabilistic CYK Parser
Overview We wish to parse sentences given specific grammar rules and their production probabilities over a corpus. Using the added probabilities of production rules and bottom up dynamic programming, more specifically the CYK Parsing Algorithm we can generate the most likely parse tree. The parsing algorithm is tested on a subset of the WSJ treebank dataset. Over 10,000 grammar production rules are utilized to produce parse trees for new sentences.
1. Parsing
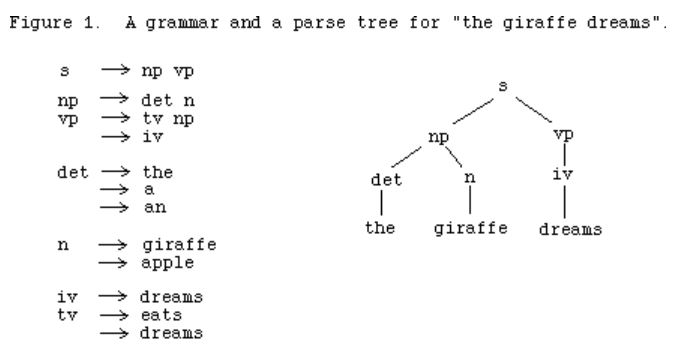
Parsing in NLP is the process of determining the syntactic structure of a text by analyzing its words according to an underlying grammar. A grammar is composed of multiple terminals (tokens), non-terminals (grammatical entities such as “noun phrase”), and associated rules that generate the terminals and non-terminals. An example of a grammar and a parse tree for the sentence “the giraffe dreams” is shown below 1 . Successfully parsing novel sentences is a pivotal component of many NLP applications including machine translation as well as infering semantic meaning as evidenced in question answering systems.
2. Probabilistic CYK Parsing
The extended Cocke–Younger–Kasami (CYK) algorithm for given probabilistic context-free grammars (PCFGs) is an inference algorithm that utilizes dynamic programming to find the most likely parse tree of a given sentence according to production probabilities. The CYK algorithm has a worst case running time of O(n^3 * |G|) where G is the size of the grammar. The CYK algorithm requires our Context Free Grammar (CFG) G to be in Chomsky Normal Form meaning that all production rules either produce 1 or 2 nonterminals or exactly 1 terminal. A probablistic context free grammar (PCFG) consists of Σ : terminals, N : non-terminals, R: production rules with probabilities, S: start symbol. The algorithm first fills in the most likely production rules for producing the terminals and then continues upwards in a bottom up fashion using dynamic programming.
Input: A string x1…xn and PCFG = (Σ, N, R, S)
initialize scores[i,j][A] = 0 for all 0<=i<j<=n , A in N
initialize backpointer
for i in [1,n]
for A in N where (prob, A -> xi) in R
scores[i-1][i][A] <- max(prob, scores[i-1][i][A])
update backpointer
for l in [2,n]
for i in [0,n-l]
j = i+l
for k in [i+1,j-1]
for (prob, A -> BC) in R
scores[i][j][A] <- max(prob*scores[i][k][B] * scores[k+1][j][C], scores[i][j][A])
The pseudocode above gives a rough sketch of the CYK algorithm, during our application we also had to add in the unary production rules such as A->B. The scores data structure is implemented as a dictionary and allows us to track probability of the sub tree rooted at a given nonterminal A over the index i to j. The backpointer is also implemented as a dictionary and is used to remember the most optimal substructures of the tree (which production rules where used and when) and allows us to reconstruct the parse tree.
3. Results
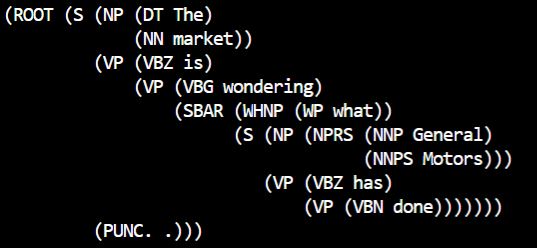
After parsing is completed we can retrieve the parse tree using the backpointer. If backpointer[0,n][S] is non-zero then we have a successful parsing. Then we continue down the tree according to the production rules until we have produced the entire sentence. For example if our first rule is S -> A B with parition i then we continue with backpointer[0,i][A] and backpointer[i,n][B] accordingly. Our algorithm successfully parsed several sentences from the WSJ Treebank. An example for “The market is wondering what General Motors has done.” is shown below.
Developed in context of NYU Graduate Natural Language Processing Course
[1]: Allen, James, Natural Language Understanding 2e, Benjamin Cummings, 1995.