Levente Szabo
M.S. Computer Science
New York University 2021
Email: levbszabo@gmail.com
View My LinkedIn Profile
DotBridge – Multimodal AI for Video: Knowledge Graphs & Voice Agents
Framework for turning passive video into interactive, queryable knowledge with real-time voice agents.
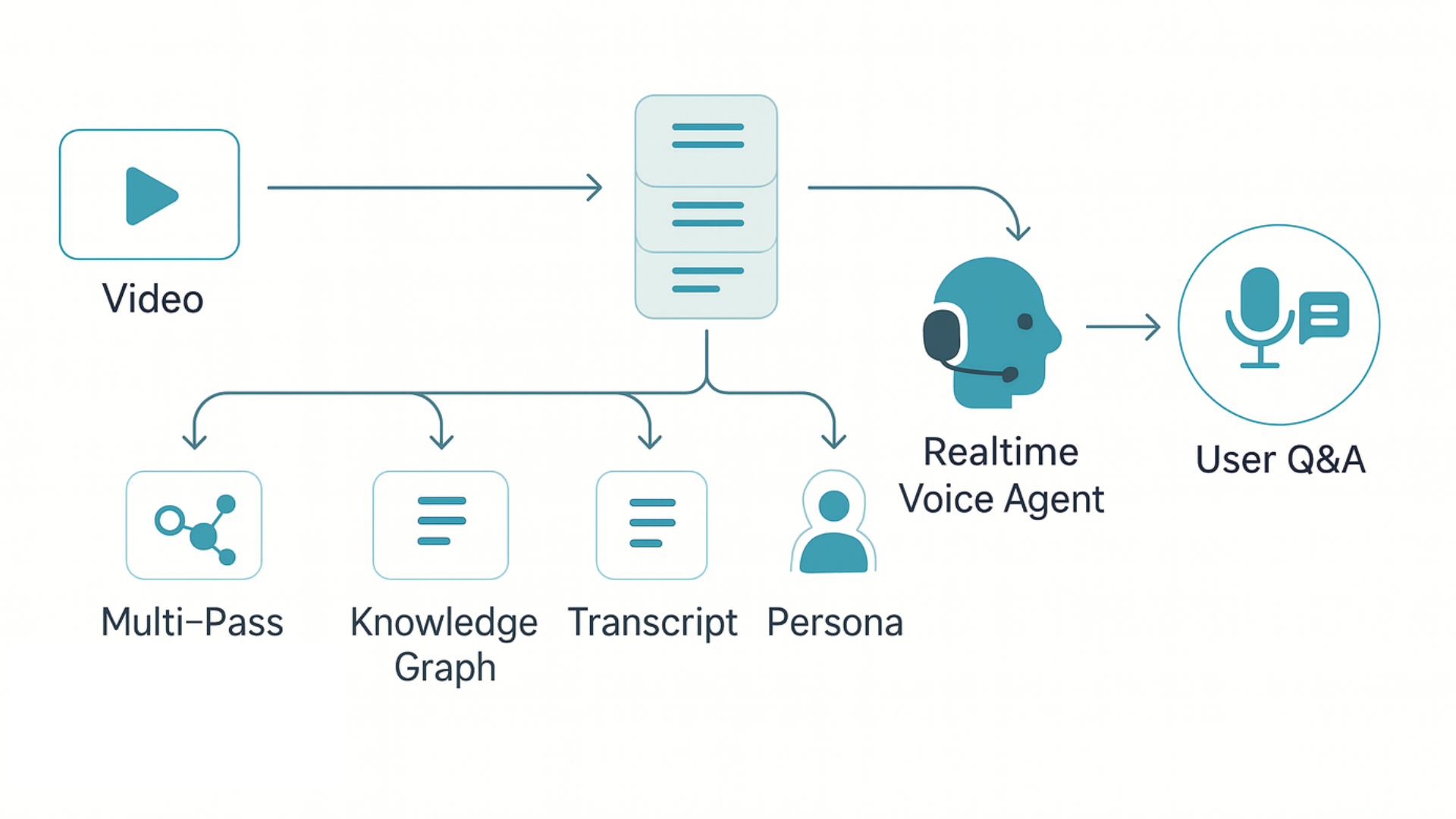
Overview: DotBridge is an open-source research framework for systematic knowledge extraction from multimodal content (video, audio, text). It converts raw videos into temporally aligned transcripts and structured knowledge graphs, then orchestrates LLMs and real-time voice to enable interactive, conversational Q&A grounded in the source content. Originally built as a commercial product, it is now open-sourced to advance research in agent architectures, knowledge graph construction, and real-time AI.
At a Glance
- Processes ~10-minute videos in ~30 seconds for extraction
- Sub-200ms real-time voice agent responses via streaming
- ~7.4k lines across Python backend and React frontend
- Stack: Python, Flask, React, Gemini 2.0/2.5, GPT‑4, LiveKit, Deepgram, Cartesia, SQL/embeddings, AWS
Key Innovations
- Multipass Content Analysis: Transcribes and segments video/audio; performs structured extraction to build a timestamp-aligned knowledge graph of entities, topics, and relationships.
- Real-Time LLM Orchestration: Integrates Gemini 2.0/2.5 and GPT‑4 with low-latency audio streaming (WebRTC via LiveKit) to power sub‑200ms voice agents that answer questions about the video in real time.
- Interactive Q&A + Voice Synthesis: Combines ASR (Deepgram), LLM-driven reasoning, and TTS (Cartesia) to deliver natural voice-based interaction for education, research, and product demos.
- Knowledge Graph Construction: Generates a structured, queryable representation (concepts, personas, timeline mappings, Q&A derivations) to support retrieval and reasoning over long-form content.
- Production-Grade Engineering: ~7.4k lines of Python + React across extraction and agent systems, with data pipelines, storage (SQL/embeddings), and a web UI; designed for reliability and real-time performance.
Results & Impact
- Latency and Throughput: Processes ~10-minute videos in ~30 seconds for extraction; real-time agent responses under ~200ms with optimized streaming.
- Research Utility: Turns passive videos (e.g., earnings calls, webinars) into interactive, queryable knowledge sources, enabling new workflows for multimodal retrieval and insight discovery.
- Applied Finance: Demonstrated interactive analysis of financial presentations and research content, bridging unstructured media and structured analysis.
Tech Stack
Python (3.8+), Flask, React (18+), Google Gemini 2.0/2.5, OpenAI GPT‑4, LiveKit (WebRTC), Deepgram (ASR), Cartesia (TTS), LangChain, PostgreSQL/SQLite, AWS S3, Docker.
Links
- GitHub Repository: levbszabo/dotbridge
- System Design (in repo): https://github.com/levbszabo/dotbridge/blob/main/SYSTEM_DESIGN.md
Note: This project was initially pursued commercially. I realized my strengths and interests align most with research and engineering, so I open-sourced DotBridge to contribute to the community and focus on advancing multimodal AI research.
References: GitHub – DotBridge
How It Works
- Ingest video/audio and documents
- Transcribe, segment, and align timeline
- Extract entities, topics, and relations into a timestamped knowledge graph
- Index for retrieval and reasoning (LLM-driven)
- Serve real-time conversational agent (ASR → LLM → TTS) over WebRTC
Use Cases
- Financial research: earnings calls, webinars, slide walkthroughs
- Education: lecture exploration and interactive study aids
- Product onboarding: interactive tutorials and support
Getting Started
# Clone and setup
git clone https://github.com/levbszabo/dotbridge.git
cd dotbridge
python -m venv venv && source venv/bin/activate
pip install -r backend/requirements.txt
# Configure
cp config.txt backend/.env
# Edit backend/.env with at least GOOGLE_API_KEY
# Extract knowledge from your content
python quickstart_extraction.py --video /path/to/video.mp4 --document /path/to/document.pdf